Automated unit test generation is essential for robust software development, yet existing approaches struggle to generalize across multiple programming languages and operate within real-time development. While Large Language Models (LLMs) offer a promising solution, their ability to generate high coverage test code depends on prompting a concise context of the focal method. Current solutions, such as Retrieval-Augmented Generation, either rely on imprecise similarity-based searches or demand the creation of costly, language-specific static analysis pipelines.
To address this gap, we present LSPRAG, a framework for concise-context retrieval tailored for real-time, language-agnostic unit test generation. LSPRAG leverages off-the-shelf Language Server Protocol (LSP) back-ends to supply LLMs with precise symbol definitions and references in real time. By reusing mature LSP servers, LSPRAG provides an LLM with language-aware context retrieval, requiring minimal per-language engineering effort.
We evaluated LSPRAG on open-source projects spanning Java, Go, and Python. Compared to the best performance of baselines, LSPRAG increased line coverage by up to 174.55% for Golang, 213.31% for Java, and 31.57% for Python.

Problem: Existing RAG and tooling fail to retrieve precise, dependency-aware context in real time across languages.
Insight: Modern IDEs ship mature analyzers exposed through LSP. Querying LSP for definitions and references provides exact, language-aware context without building language-specific analyzers.
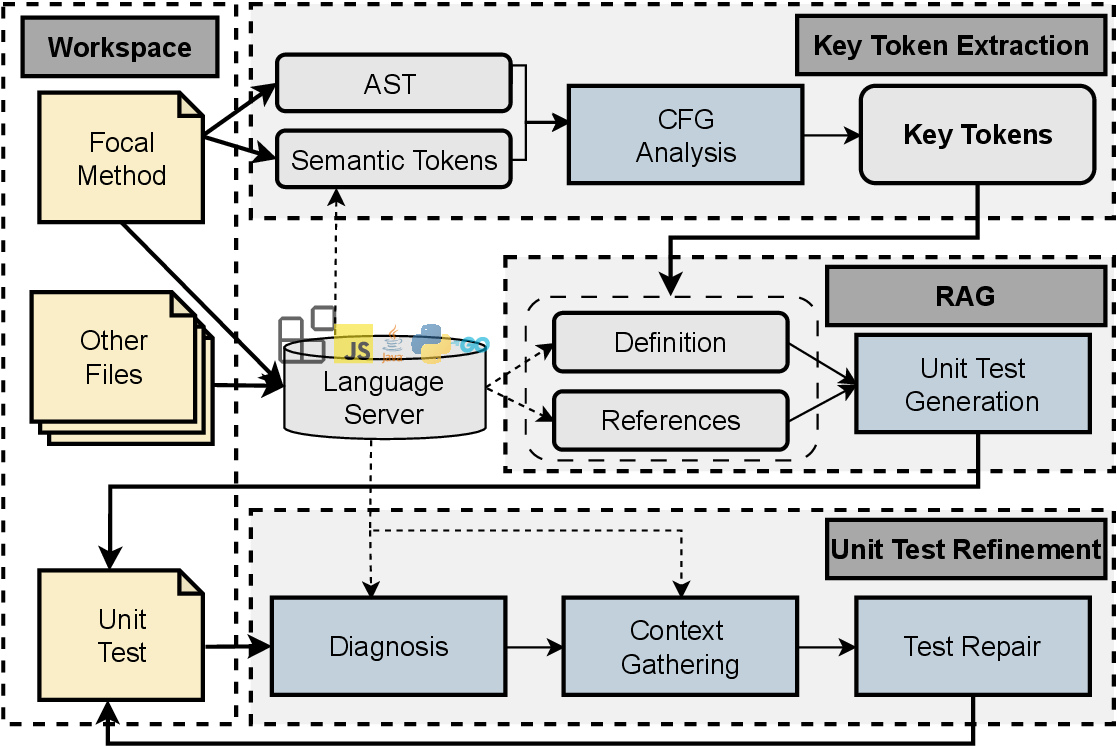
System Design
if you interested in specific explanation, look further into paper.
- Key Token Extraction: Identify tokens governing control flow and dependencies via hybrid LSP lexical data and AST structure.
- RAG on LSP: Retrieve precise symbol definitions and enriched usage references via LSP DEF/REF to build focused prompts.
- Unit Test Refinement: Compilation-free loop using LSP diagnostics to detect and fix syntax errors in generated tests.
Overall Experiments
If you want to reproduce our experiment, click here
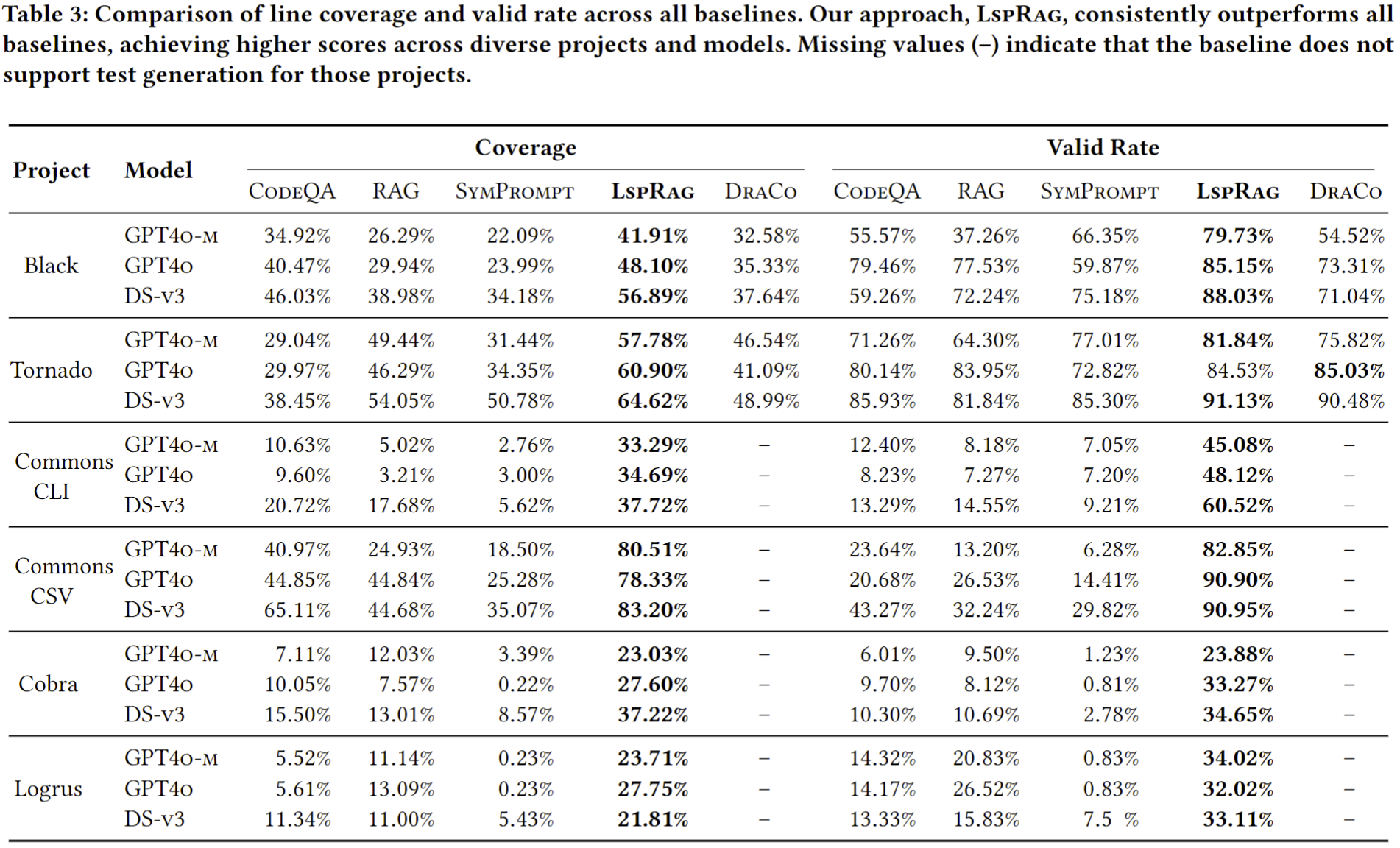
This overall results show that LSPRAG consistently improves line coverage across all projects, regardless of the programming language or the underlying LLM. LSPRAG's strong performance stems from two primary mechanisms. First, for higher coverage, LSPRAG leverages LSP features like "go to definition" and "find references" to construct a precise semantic dependency graph. This provides the LLM with a complete yet concise context, avoiding the noise of generic RAG and the intra-file blind spots of other methods. Second, to achieve a higher valid rate, LSPRAG utilizes real-time diagnostics on top of LSP to detect and correct syntactic errors in the generated code iteratively. This self-correction loop consistently improves the valid rate of generated test cases, as evidenced by the consistently high valid rates. For detailed explanation, please refer to the paper.
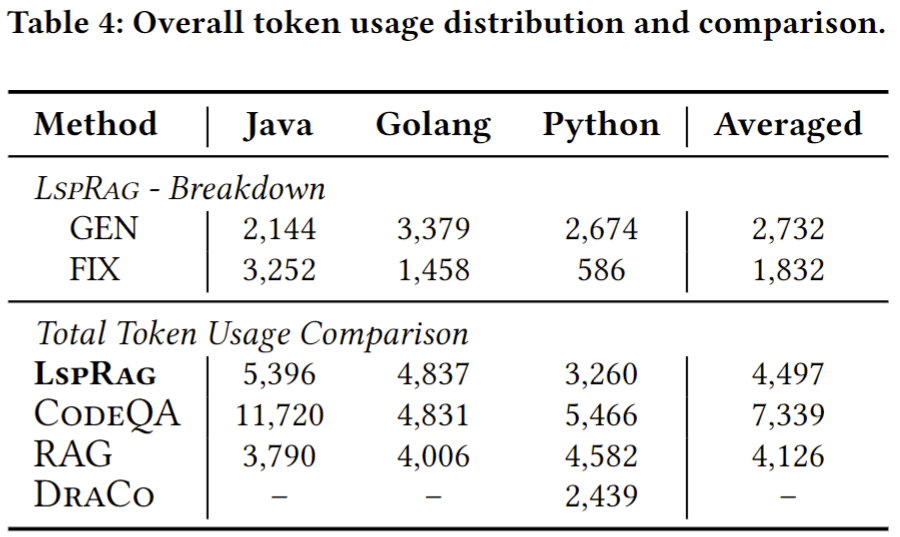
LSPRAG averagely uses 2,732 tokens for the initial generation and 1,832 for fixing. While LSPRAG's token consumption is not the lowest in all cases, we consider the gains in coverage justify the trade-off. For instance, compared to CodeQA, LSPRAG uses 39% fewer tokens while achieving a 135% improvement in coverage. When measured against Draco, LSPRAG uses 9.6% more tokens for generation and 24% more for fixing, but these increases yield coverage improvements of 30% and an additional 6%, respectively. Furthermore, LSPRAG demonstrates its efficiency against a RAG approach, delivering a 174% coverage improvement with an 8.9% increase in total tokens used for generation and fixing.
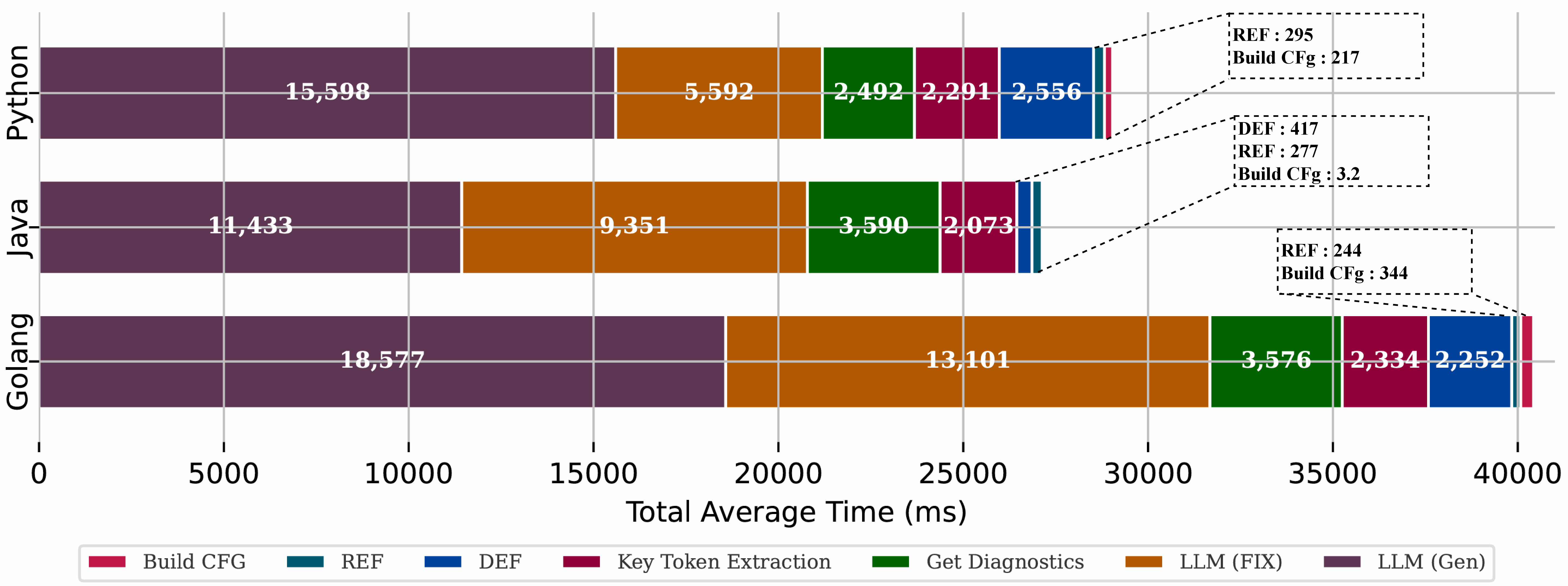
On average, our tool requires 28.27 seconds and 4,497 tokens per focal method to generate and refine a unit test. As detailed in figure, the majority of this time (approximately 70%) is spent on LLM API querying for generation and refinement. Our retrieval strategy, which includes key token extraction and leveraging the LSP for reference and definition providers, accounts for about 5 seconds of the total time. While the refinement stage constitutes over 30% of the generation time, we consider this a necessary and acceptable trade-off for the improvements it yields in both line coverage and the rate of valid tests.
VSCode Extension
LSPRAG is available as a VS Code extension that integrates Language Server Protocol for semantic analysis and leverages LLMs to generate high-quality unit tests.
→ View Complete Extension Documentation
The extension documentation includes:
- Step-by-step installation guide
- Usage instructions with screenshots
- Detailed system architecture analysis
- Core module explanations
- Configuration options reference
Citation
If you use LSPRAG in your research, please cite the paper.
@inproceedings{GoLSPRAG2026icse,
author = {{Gwihwan Go} and {Quan Zhang} and {Chijin Zhou} and {Zhao Wei} and {Yu Jiang}},
title = {LSPRAG: LSP-Guided RAG for Language-Agnostic Real-Time Unit Test Generation},
year = {2026},
isbn = {979-8-4007-2025-3},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
doi = {10.1145/3744916.3773189},
booktitle = {Proceedings of the 48th International Conference on Software Engineering},
location = {Rio de Janeiro, Brazil},
series = {ICSE '26}
}